
Le 2 octobre 2025, j’ai créé une page expérimentale sur mon site https://guychefaitdestests.com/nova-lumina/. Cette page présente une chaussure entièrement fictive, dont les caractéristiques ont été inventées avec l’aide de ChatGPT.

L’objectif de ce test était de construire une page intégralement en JavaScript afin d’observer la manière dont différents grands modèles de langage allaient l’interpréter.
Pour ceux qui l’ignorent, JavaScript joue un rôle essentiel dans la construction des pages web modernes. Contrairement au HTML, qui structure le contenu, et au CSS, qui gère la mise en forme, le JavaScript permet de rendre une page interactive et dynamique. C’est lui qui permet d’afficher des éléments au clic, de créer des animations ou encore de générer des données directement côté navigateur. En plus, Google aime et exige le JS. C’est pour ces raisons que de nombreux sites utilisent des frameworks JS (comme React, Vue ou Angular) : ils offrent une expérience plus fluide à l’utilisateur.
Dans ce test, l’idée était justement de voir si les LLMs sont capables de comprendre une page qui ne repose que sur du JS, sans HTML statique.
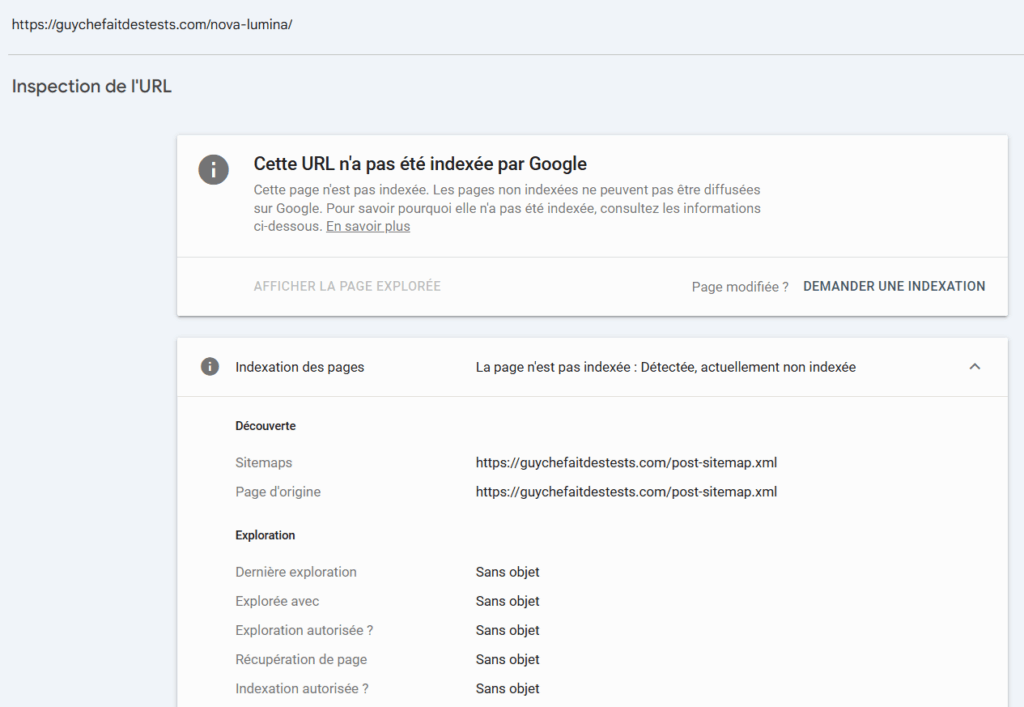
Pour éviter toute indexation par Google, j’ai mis en place plusieurs mesures: J’ai ajouté une balise noindex à la page. J’ai désindexé également toutes les images. Pour être sûr que la page n’avait pas été indexée par Google, j’ai ensuite vérifié dans la Search Console puis avec la commande site: dans Google que l’URL et ses images n’apparaissaient pas. Enfin, j’ai configuré le fichier robots.txt avec les instructions suivantes :
User-agent: Googlebot
Disallow: /nova-lumina/
L’idée derrière cette démarche était d’écarter totalement Google et voir si les LLMs peuvent se débrouiller tous seuls comme des grands. En effet, il se raconte que certains modèles de langage s’appuient sur des services d’entreprise comme SerpAPI pour interroger la SERP de Google et récupérer des pages web. Je voulais donc que la page ne puisse en aucun cas être visible dans Google, ceci afin de vérifier uniquement la capacité des LLMs à exécuter du JavaScript.
Moins de 5 minutes après avoir mis en ligne la page, j’ai lancé mes tests sur plusieurs modèles : Perplexity, Mistral, Gemini, ChatGPT, DeepSeek et Bing Copilot. Pour chacun, j’ai posté la même requête (on dit également prompt) :
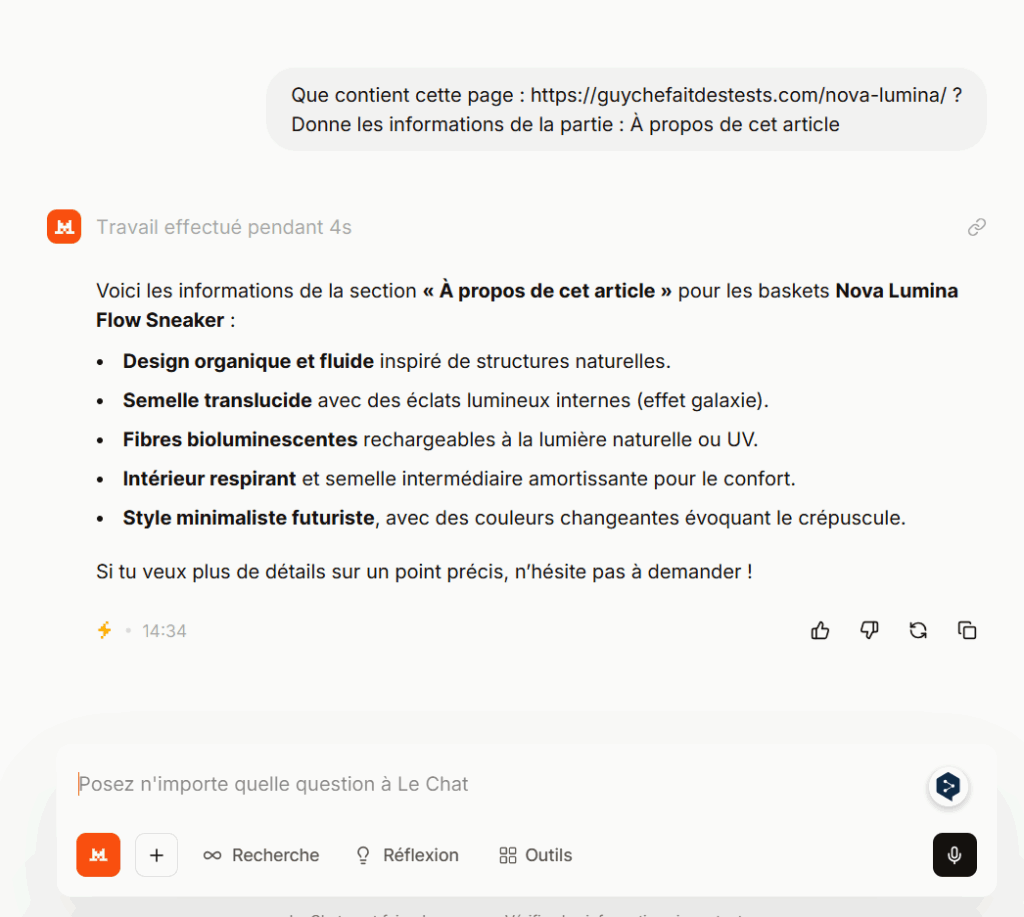
Que contient cette page : https://guychefaitdestests.com/nova-lumina/ ?
Donne les informations de la partie : À propos de cet article
voici la capture que j’ai faite pour la Search Console:
J’ai fait d’autres captures pour vous montrer les résultats affichés par les LLMs.
Perplexity, en mode recherche approfondie, a été capable d’exécuter le JavaScript et d’afficher le contenu complet de la page.
Mistral a également su restituer les informations.
Bing Copilot tout naturellement est parvenu lui aussi à exécuter le JS et à afficher correctement le contenu. En revanche, ni Gemini ni ChatGPT n’ont pu exécuter le script et rendre le JS. L’échec de DeepSeek était également prévisible.
Un fait m’a paru étrange : le samedi 11 octobre 2025 soit plus d’une semaine après mes plus d’une semaine après mes tests réalisés le 02 octobre 2025, Bing n’arrive toujours pas à indexer la page. Je constate qu’une page bloquée dans le robots.txt pour Google est aussi bloquée pour Bing, il n’apparait pas dans la SERP de Bing.
Ce test met en évidence une différence majeure dans la façon dont les LLMs traitent le contenu des pages web.
Selon ce que j’ai constaté et compris, deux (2) modèles simulent le travail d’un navigateur web : ils ne se contentent pas de lire le code source ; ils suivent les instructions de la page (JavaScript) pour reconstruire l’affichage final.
Les autres, en revanche, font de l’analyse statique : ils ne lisent que le code initial (HTML) sans exécuter les scripts. Ils n’ont donc accès qu’à la structure initiale, et non aux éléments qui apparaissent dynamiquement.
Dans un précédent test, j’avais montré que lorsque le contenu généré dynamiquement est indexé par Google, à ce moment ChatGPT Search a accès à ce contenu. C’est ainsi que j’avais prouvé que ChatGPT ne faisait pas que juste scraper la SERP de Google, il avait également accès au contenu indexé par Google: voir le test et le résumé sur LinkedIn des résultats constatés: voir la publication (je rédigerai un article plus détaillé pour expliquer la démarche que j’ai suivie.
Ce test m’a permis de constater plusieurs faits que je peux résumer ainsi :
Bloquer Googlebot dans le fichier robots.txt constitue souvent un signal de non-exploration. Cette directive est également respectée par de nombreux autres crawlers d’indexation ou d’entraînement, comme Bingbot et GPTBot, ce qui peut les conduire à ignorer la ressource.
En revanche, certains systèmes de recherche ou de récupération de contenu alimentant des LLM, comme ceux utilisés par Perplexity, Mistral ou Bing Copilot, peuvent, dans certains cas, récupérer la page via un moteur de rendu, exécuter le JavaScript et reconstruire le DOM final, même lorsque l’URL n’est pas explorée par les crawlers classiques.
Pour les éditeurs et propriétaires de sites web, il est important de comprendre que certains LLMs peuvent restituer le contenu d’une page lorsqu’elle est déjà accessible ou indexée par Google.
Cependant, avec les restrictions de crawl, de rendu et d’accès aux contenus que Google met en place et renforce progressivement, il serait risqué de compter uniquement sur cette passerelle indirecte pour obtenir du contenu.
Si l’objectif est de rendre un contenu lisible et exploitable par les modèles d’IA, la meilleure approche reste de proposer une version HTML statique ou, au minimum, un rendu hybride permettant aux bots de récupérer les informations essentielles sans dépendre de l’exécution du JavaScript.